Exporting test runs to Splunk

Experimentation is part of the learning process. Quite often I'm challenged with trying out new tools, integrate with them, learn from them. I do like challenges. This week someone asked about exporting information (i.e., test runs) from a well-known test management solution, Xray, where I work btw, to Splunk. I was intrigued by this; first, I know Splunk for years but never used it in real projects, at least that I remember :) second, I didn't understand the exact value offer nor if it was feasible!
This post I about sharing my learnings and how I got it working.
Background
Xray
Xray is a well-known test management solution that works highly integrated with Jira (it needs it, actually). Xray cloud (i.e., for Jira cloud) provides a REST API and a GraphQL API. The latter is more powerfull and that's the one we can use to extract the test runs.
Splunk
Splunk Cloud Platform is a data oriented platform used to search, visualize, and process data from multiple sources, providing analytics and observability kind of capabilities.
How to
The first step is to extract data from Xray cloud. To achieve this, I've implemented some code in JavaScript.
The code ahead uses a JQL expression to define the source of the data; in this case, I aim to export all test runs from project "CALC" in Jira, based on the related Test Execution issues. We need to obtain the related issue ids (Jira internal ids) of these, as the getTestRuns GraphQL function requires us to pass them (or the Test issue ids, if we prefer to obtain test runs based on that).
The code also has some basic logic to deal with pagination on the GraphQL requests; more error handling should be provided btw as, for example, the API can return temporary errors or rate limiting errors.
There's also logic to export test runs based on a modification date, and use that to avoid exporting them on next export operations.
var axios = require('axios');
const { GraphQLClient, gql } = require('graphql-request')
const fs = require('fs');
var xray_cloud_base_url = "https://xray.cloud.getxray.app/api/v2";
var xray_cloud_graphql_url = xray_cloud_base_url + "/graphql";
var client_id = process.env.CLIENT_ID || "215FFD69FE4644728C72182E00000000";
var client_secret = process.env.CLIENT_SECRET || "1c00f8f22f56a8684d7c18cd6147ce2787d95e4da9f3bfb0af8f02ec00000000";
var authenticate_url = xray_cloud_base_url + "/authenticate";
// Jira JQL query to define the list of Test Execution issues to export test runs from
jql = "project=CALC and issuetype = 'Test Execution'"
async function getTestExecutionIds (jql, start, limit) {
return axios.post(authenticate_url, { "client_id": client_id, "client_secret": client_secret }, {}).then( (response) => {
var auth_token = response.data;
const graphQLClient = new GraphQLClient(xray_cloud_graphql_url, {
headers: {
authorization: `Bearer ${auth_token}`,
},
})
// console.log(auth_token);
const testexec_ids_query = gql`
query
{
getTestExecutions(jql: "${jql}", limit: ${limit}, start: ${start}) {
results{
issueId
}
}
}
`
return graphQLClient.request(testexec_ids_query).then(function(data) {
testexec_ids = data['getTestExecutions']['results'].map(function(t){
return t['issueId'];
});
// console.log(testexec_ids);
return testexec_ids;
}).catch(function(error) {
console.log('Error performing query to obtain Test Execution ids: ' + error);
});
}).catch( (error) => {
console.log('Error on Authentication: ' + error);
});
}
async function getTestRuns (testExecIssueIds, start, limit, modifiedSince) {
return axios.post(authenticate_url, { "client_id": client_id, "client_secret": client_secret }, {}).then( (response) => {
var auth_token = response.data;
const graphQLClient = new GraphQLClient(xray_cloud_graphql_url, {
headers: {
authorization: `Bearer ${auth_token}`,
},
})
testexec_ids = testExecIssueIds.map(function(t){
return '"' + t + '"';
}).join(',');
// console.log(testexec_ids);
const query = gql`
{
getTestRuns(testExecIssueIds: [${testexec_ids}], limit: ${limit}, start: ${start}, modifiedSince: "${modifiedSince}" ) {
total
start
results{
id
status{
name
description
}
comment
evidence{
filename
downloadLink
}
defects
executedById
startedOn
finishedOn
assigneeId
testType{
name
}
steps {
id
action
data
result
customFields {
name
value
}
comment
evidence{
filename
downloadLink
}
attachments {
id
filename
}
defects
actualResult
status {
name
}
}
scenarioType
gherkin
examples {
id
status {
name
description
}
duration
}
unstructured
customFields {
id
name
values
}
preconditions(limit:10) {
results{
preconditionRef {
issueId
jira(fields: ["key"])
}
definition
}
}
test {
issueId
jira(fields: ["key"])
}
testExecution {
issueId
jira(fields: ["key"])
}
}
}
}
`
return graphQLClient.request(query).then(function(data) {
//console.log(JSON.stringify(data['getTestRuns']['results'], undefined, 2))
return data['getTestRuns']['results'];
// testruns.push(data['getTestRuns']['results'])
}).catch(function(error) {
console.log('Error performing query to obtain testruns: ' + error);
});
}).catch( (error) => {
console.log('Error on Authentication: ' + error);
});
}
/**** main *****/
(async () => {
let configFile = 'export_testruns.json'
if (!fs.existsSync(configFile)) {
fs.writeFileSync(configFile, "{}")
}
let config = JSON.parse(fs.readFileSync(configFile));
let modifiedSince = config['modifiedSince'] || "2021-01-01T00:00:00Z"
// obtain Test Execution issue ids
let start = 0
let limit = 100
let testexecs = []
let tes = []
do {
tes = await getTestExecutionIds(jql, start, limit)
start += limit
testexecs.push(...tes)
} while (tes.length > 0)
// obtain the Test Runs for the given Test Execution issue ids, modified since a given data
let testruns = []
start = 0
let trs = []
do {
trs = await getTestRuns(testexecs, start, limit, modifiedSince)
start += limit
testruns.push(...trs)
} while (trs.length > 0)
console.log(JSON.stringify(testruns, undefined, 2))
fs.writeFileSync('testruns.json', JSON.stringify(testruns));
config['modifiedSince'] = new Date().toISOString().split('.')[0]+"Z"
fs.writeFileSync(configFile, JSON.stringify(config));
})();
The previous script will generate a testruns.json file, having an array of JSON objects, each one corresponding to a test run.
Now we need to import it to Splunk. In Splunk we have events; our test runs will be abstract as Splunk events.
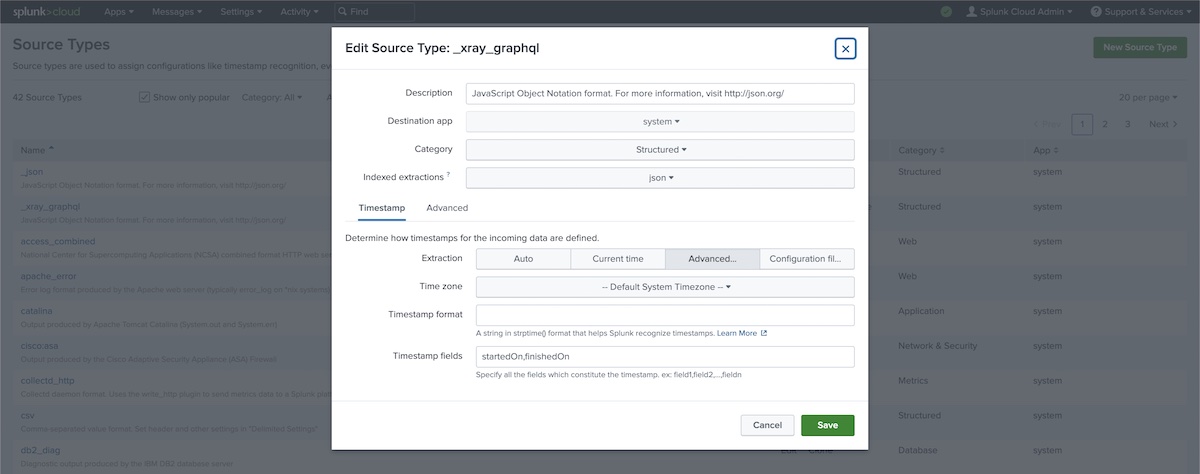
In Splunk, we start by creating a new "source type", and name it (e.g., "_xray_graphql"). Go to Settings > Source Types and choose a structured, JSON kind of source. Specify the timestamp fields (e.g., "startedOn", "finishedOn"); these fields should be present on ech test run JSON object.
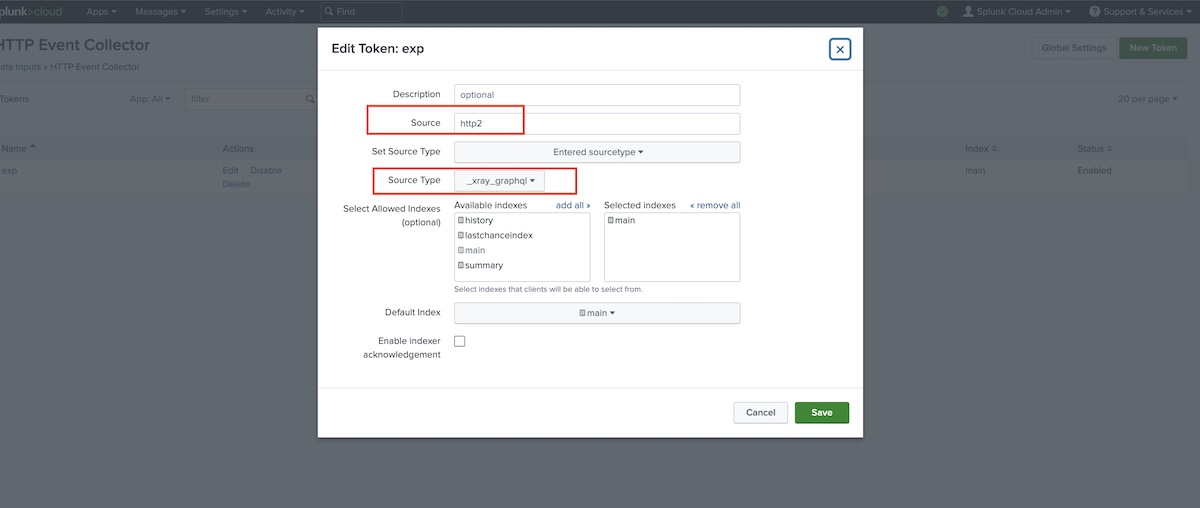
Then, we define a new data input, by creating a token for the HTTP Event Collector (HEC).
Go to Settings > Data Inputs and select the HTTP Event Collector, and make sure you select the source type created earlier.
We can submit one event or multiple events at once using the HTTP Event Collector instance/token we created. In this case, we'll submit an array with multiple test runs.
I've created a shell script import_testruns_to_splunk.sh to assist me on this.
#!/bin/bash
FILE=$1
curl -k https://prd-p-ys24n.splunkcloud.com:8088/services/collector/raw -H "Authorization: Splunk 75db55f8-b89f-4bc5-0000-00000000" -X POST -H "Content-Type: application/json" -d @"$FILE"
I can then import the test runs as follows.
$ ./import_runs_to_splunk.sh testruns.json
{"text":"Success","code":0 }
These events (i.e., our test runs) will be assigned to the source we identified (e.g., "http2"). We can then use that to filter them later on.
Using Splunk to analyze the test runs
Searching for testruns is straightforward.
We can search by events (i.e., our testruns), based on the source... or on the sourcetype... or using both fields; in this case the result wil be the same.
source="http2" sourcetype="_xray_graphql"
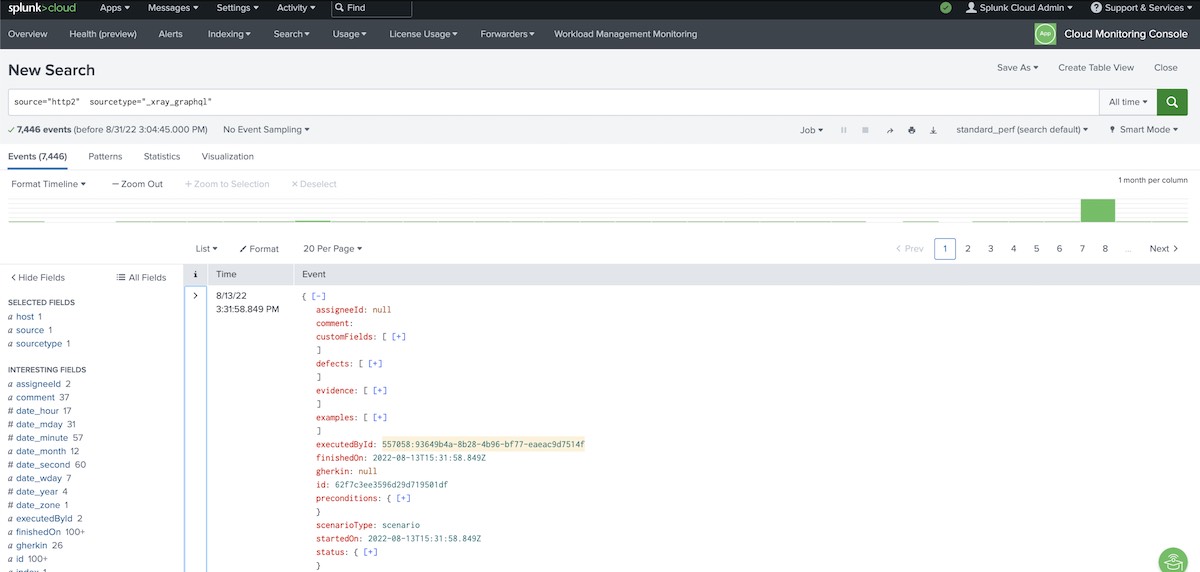
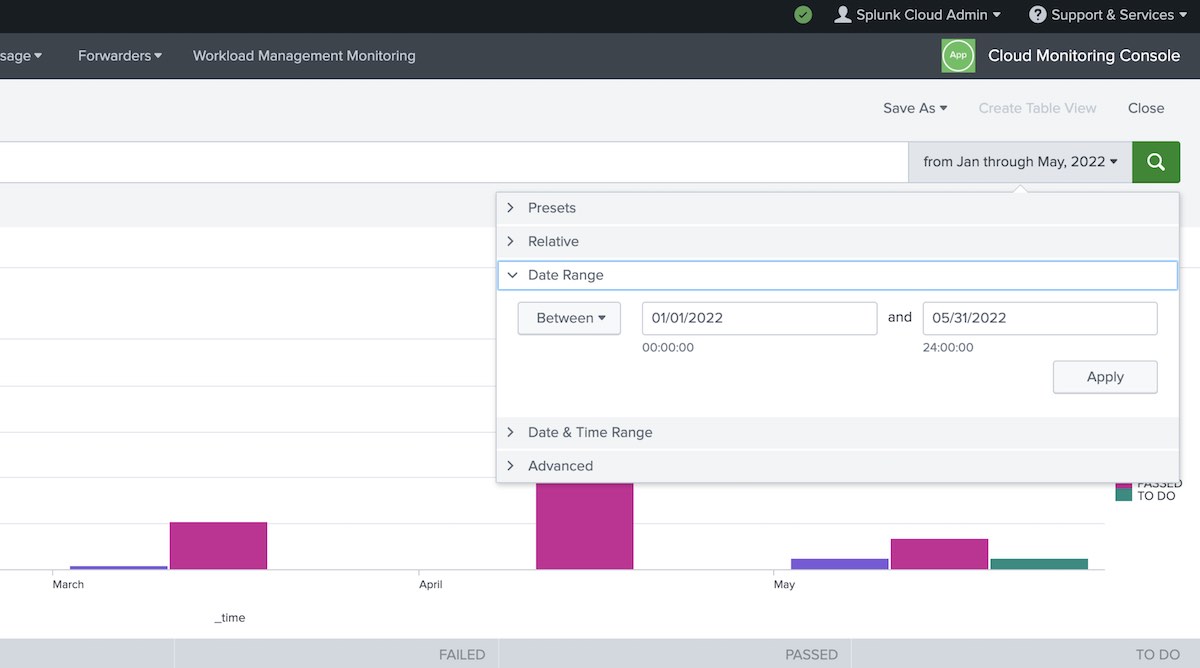
Search for successful (i.e., "passed") test runs
We can easily search by the status reported for the test run.
source="http2" sourcetype="_xray_graphql" "status.name"=PASSED
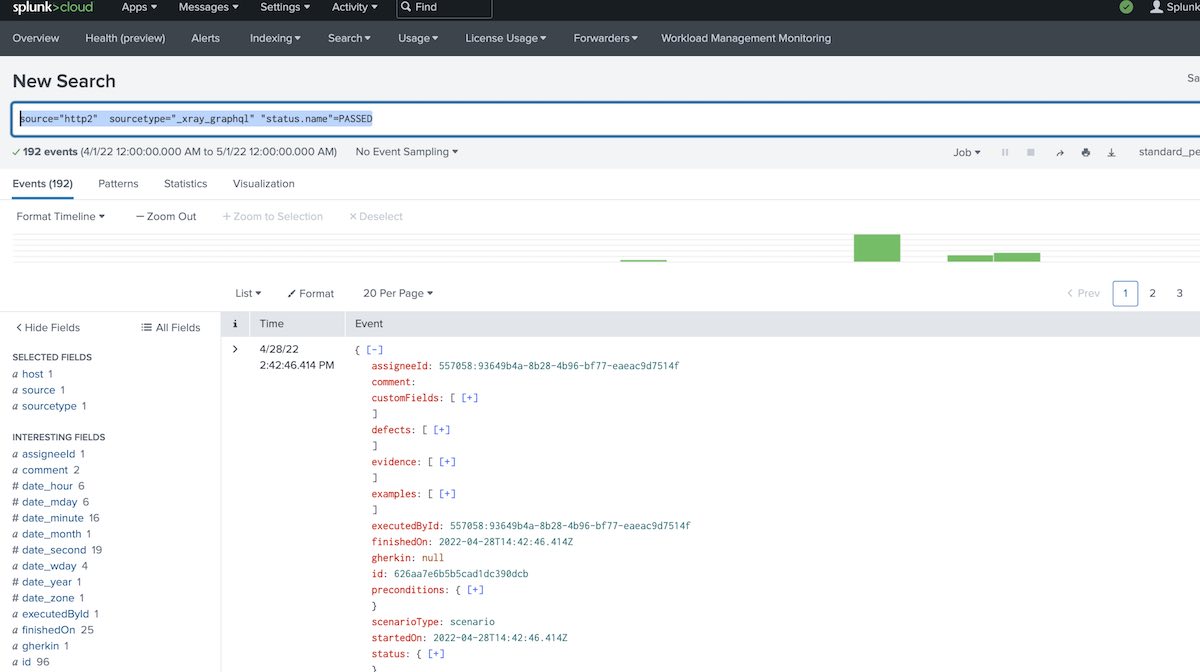
Search for test runs having a certain comment
source="http2" sourcetype="_xray_graphql" comment = "*interesting*"
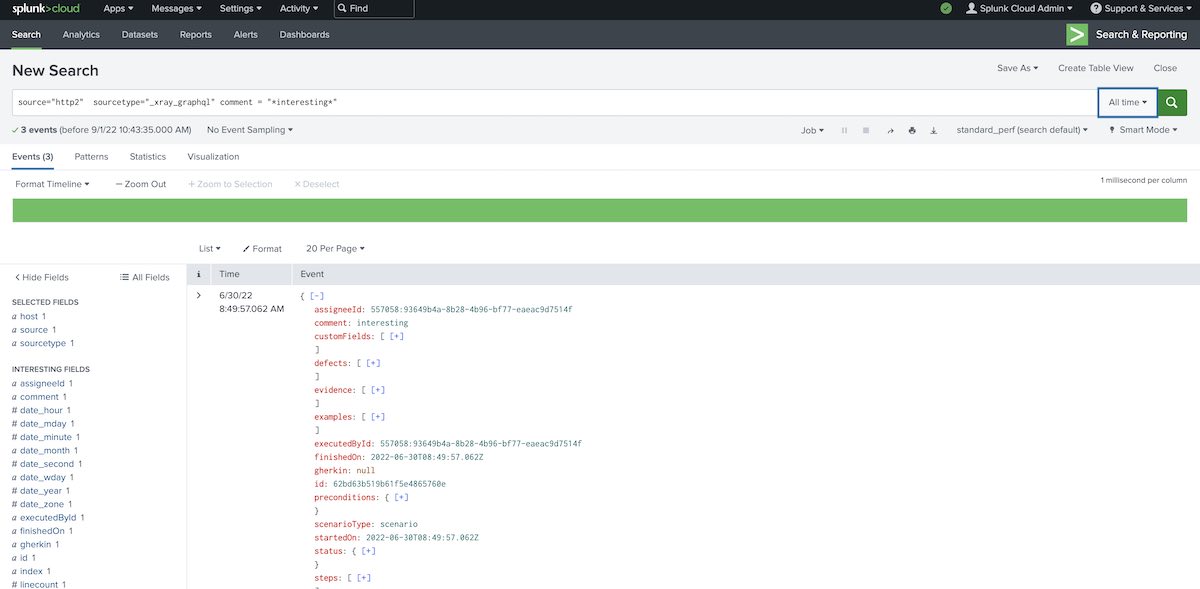
Search for test runs having linked defects
The following query will obtain the test runs having linked defects, either globally or at step-level.
source="http2" sourcetype="_xray_graphql" ("defects{}"="*" OR "steps{}.defects{}"="*")
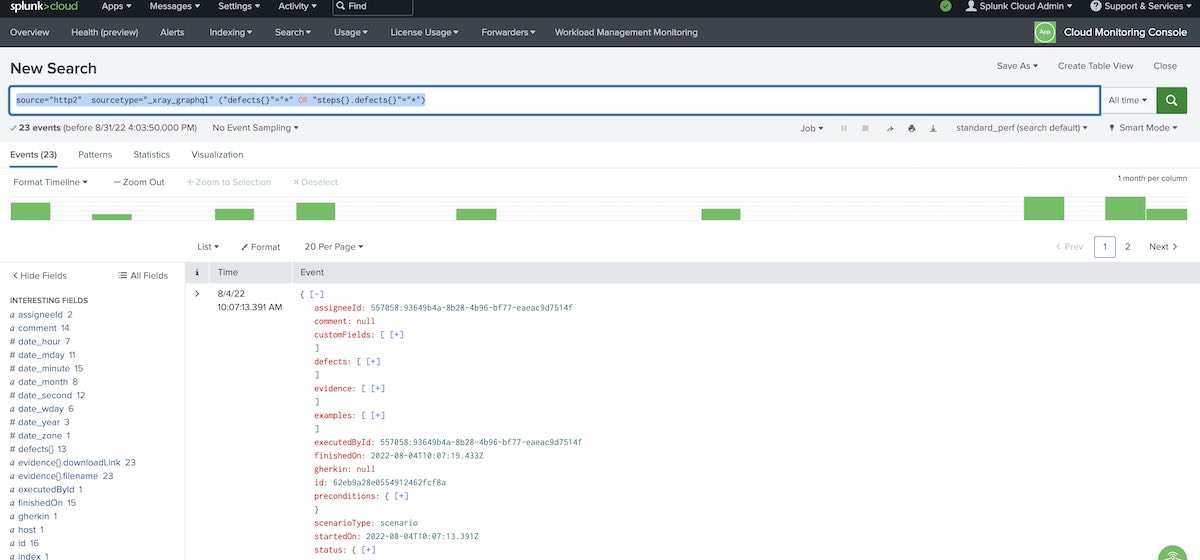
Search for test runs for a certain Test issue
source="http2" sourcetype="_xray_graphql" test.jira.key="CALC-100"
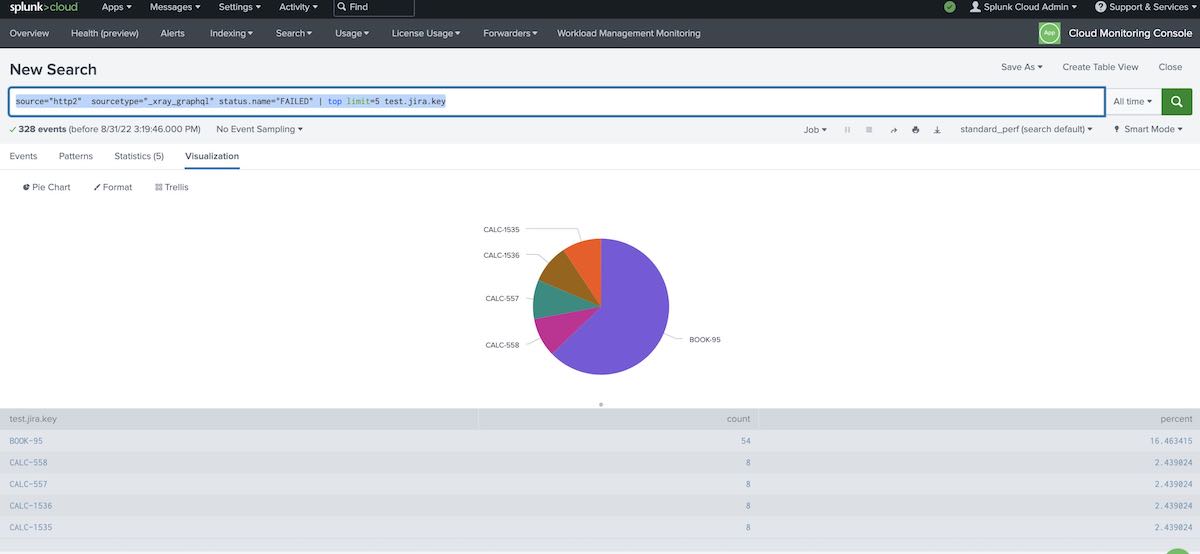
Chart: Top tests failing
source="http2" sourcetype="_xray_graphql" status.name="FAILED" | top limit=5 test.jira.key
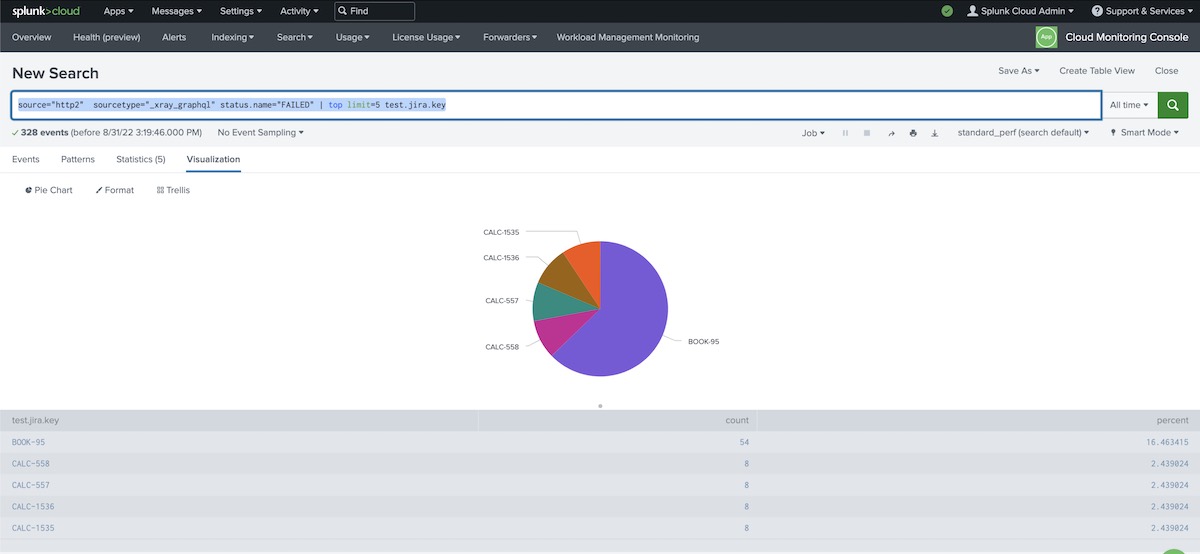
Chart: Top tests with more runs
source="http2" sourcetype="_xray_graphql" | top limit=5 test.jira.key
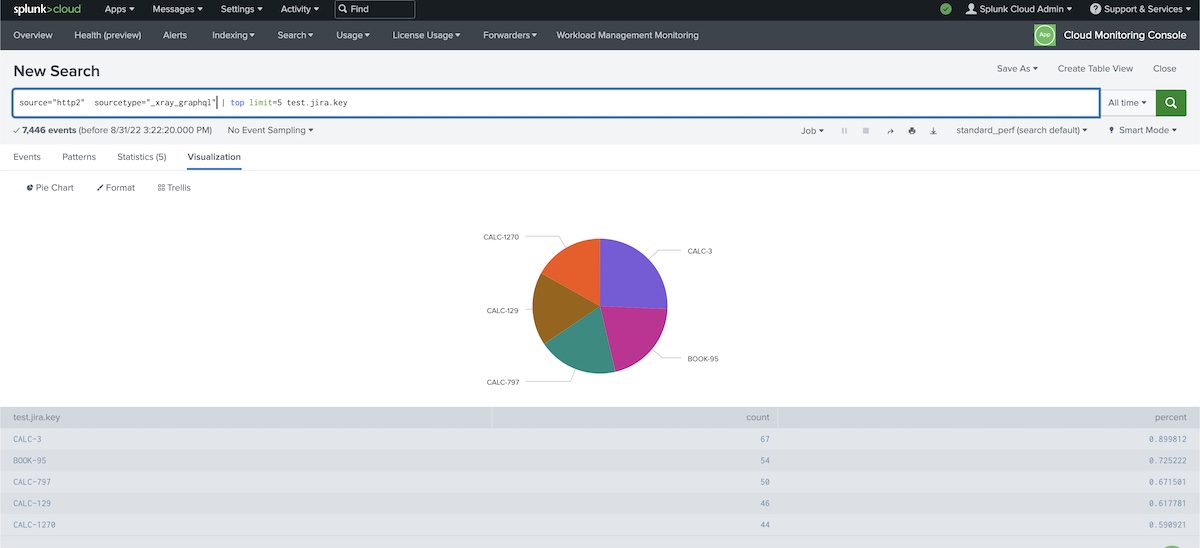
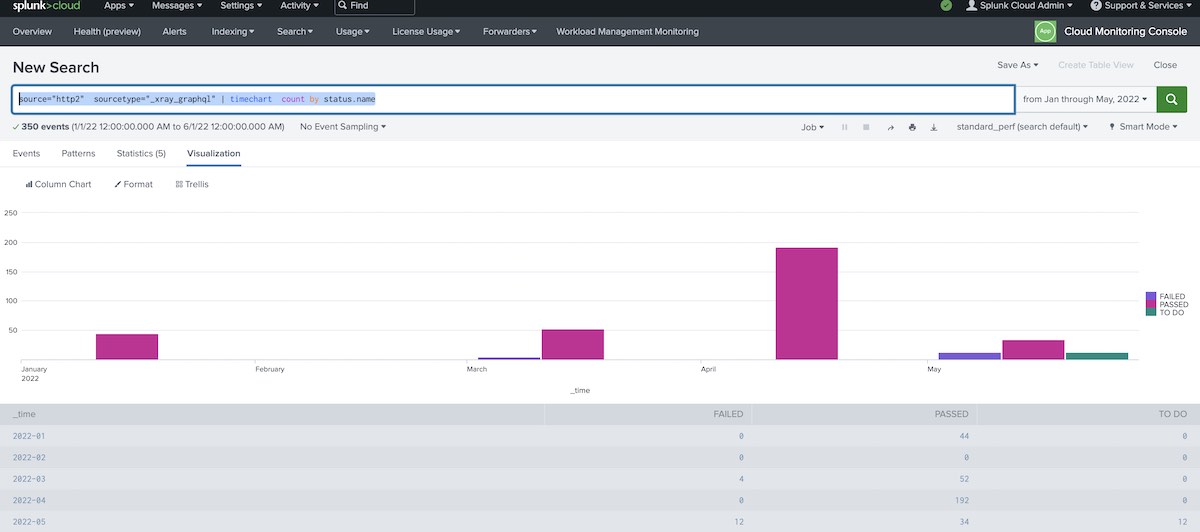
Chart: Show test results over time
source="http2" sourcetype="_xray_graphql" | timechart count by status.name
Pivot tables: show test runs count for Tests, grouped by status
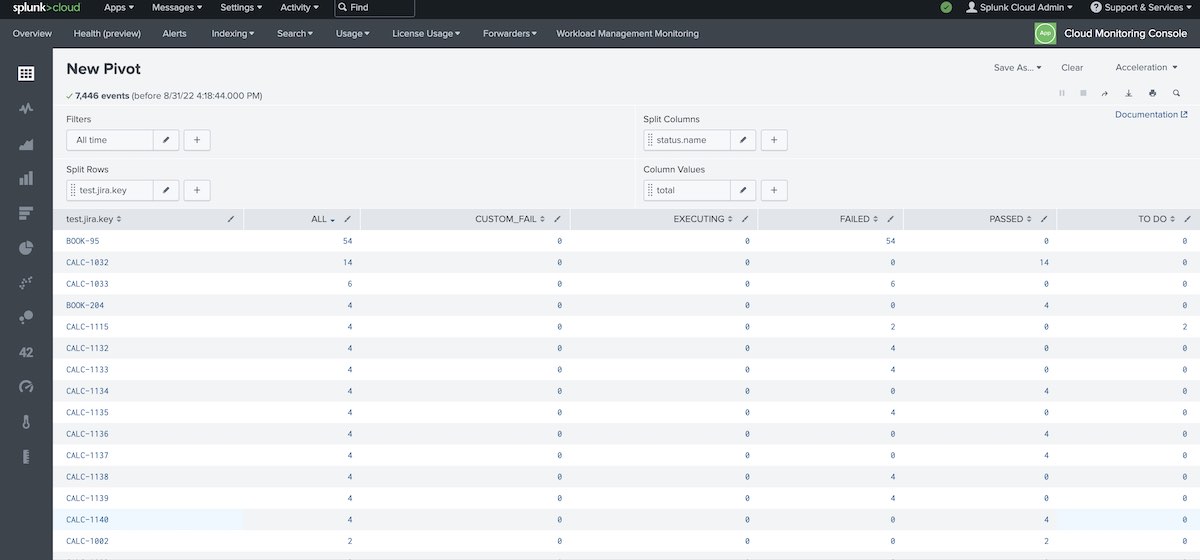
Key findings
These are a sum of my findings for this brief exercise:
- we can send an event or several events in bulk by HTTP to Splunk (we can also upload the test runs as a JSON file)
- in Splunk test runs become easily searchable
- in Splunk different types of charts can be done based on fields of the test runs
- Splunk supports pivot tables based on filed on the test runs
- it's possible to use drill-down on the charts and tables
Final considerations
This was a very interesting exercise. First, it showed how easy it could be to export information from this test management tool to another solution where we can analyze data in further detail, and eventually correlate it with something else.
Splunk provides powerfull capabilities for searching, analyzing, and visualizing data. Events can be anything we want; in this case, we used events as an abstraction for our test runs.
Additional work needs to be performed to have better control over the data that is imported and how it is represented in Splunk.
Useful references
Thanks for reading this article; as always, this represents one point in time of my evolving view :) Feedback is always welcome. Feel free to leave comments, share, retweet or contact me. If you can and wish to support this and additional contents, you may buy me a coffee ☕