AI vision in home automation


AI is all around. Can I use it for enhancing home automation scenarios?
Few days ago OpenAI released the GPT-4 vision capabilities on their API, so I thought on using AI and GPT4 vision models to analyze images of a security camera connected to a well-known home automation system: Home Assistant.
The goal was to trigger a notification to my mobile, if the system detects a potential security issue at home using AI :-)
Possible? Perhaps! Let's see!
Quick overview
Let me start by introducing some concepts.
About Home Assistant
Home Assistant is a well-known open-source home automation project that enables easy implementation of domotics / home automation systems. It is a very flexible tool that can be extended in order to provide further functionalities. In HASS, we have:
- devices
- entities, usually provided from deviced
- automations, made of "triggers", "conditions" and "actions"
- services
- ... and much more!
About the OpenAI Conversation integration
Home Assistant provides an integration with OpenAI that can:
- enable an assistant using GPT-3 language model, so that users can use the Assist feature to interact and, for example, get information about their devices and sensors using a natural language interface (e.g., english)
- generate images based on a prompt
This integration works but it doesn't provide image analysis though.
Initial challenges
I had a look at the OpenAI Conversation integration provided in Home Assistant, dive into the code and found out that it was using an old version of the OpenAI python library; I tried to bump it to the latest version but the API changed a lot so adapting the existing code was not going to be an easy task to me.
I also don't know much the Home Assistant codebase and Python is not something I use on a daily basis.
However, these challenges wouldn't stop me.
How I made it
Quick oveview
I started by creating a copy of the existing code and tried to "hack it" locally, to a local directory /custom_components/openai_conversation_custom . I had the official integration already installed which somehow conflicted with this code.
I then,
- removed the official integration from Home Assistant
- changed the
manifest.json
{
"domain": "openai_conversation_custom",
"name": "OpenAI Conversation Custom",
"codeowners": ["@balloob", "@bitcoder"],
"config_flow": true,
"dependencies": ["conversation"],
"documentation": "https://www.home-assistant.io/integrations/openai_conversation",
"integration_type": "service",
"iot_class": "cloud_polling",
"requirements": ["openai==0.27.2", "httpx"],
"version": "1.0.0-custom-20231124"
}
- did changes on the code to add additional features (more info ahead)
- installed the custom integration
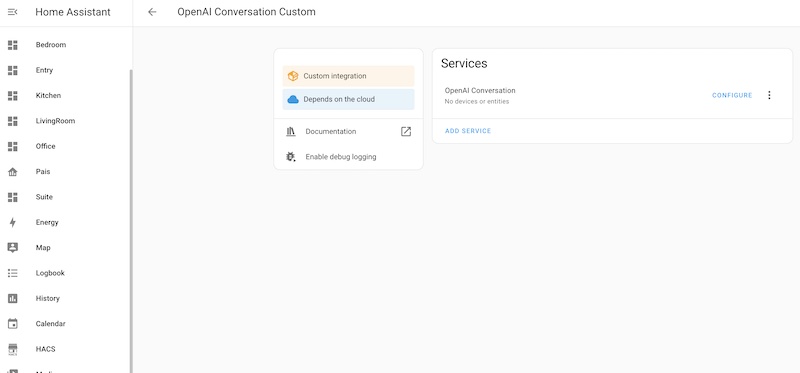
The code I added to support new features
The code that I'm about to share is not totally clean and it's like putting a parallel OpenAI client to support my needs, that include the image processing. Please consider it as a proof-of-concept and adapt it to your needs.
I created my OpenAI client inspired by Piotr Skalski and added it under the myopenai_client directory.
The code uses the `httpx`` library for making asynchronous HTTP requests.
Let me share some brief snippets of it.
import os
import numpy as np
import httpx
from .utils import compose_payload, compose_text_payload
class OpenAIConnector:
def __init__(self, api_key: str):
if api_key is None:
raise ValueError("API_KEY is not set")
self.api_key = api_key
async def simple_prompt(self, prompt: str, image_path: str = None) -> str:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
if image_path is None:
payload = compose_text_payload(prompt=prompt)
else:
payload = compose_payload(image_path=image_path, prompt=prompt)
async with httpx.AsyncClient() as client:
response = (await client.post("https://api.openai.com/v1/chat/completions",
headers=headers, json=payload, timeout=20)).json()
return response['choices'][0]['message']['content']
def compose_payload(image_path: str, prompt: str) -> dict:
"""
Composes a payload dictionary with a base64 encoded image and a text prompt for the GPT-4 Vision model.
Args:
image_path (str): The image path to encode and include in the payload.
prompt (str): The prompt text to accompany the image in the payload.
Returns:
dict: A dictionary structured as a payload for the GPT-4 Vision model, including the model name,
an array of messages each containing a role and content with text and the base64 encoded image,
and the maximum number of tokens to generate.
"""
# encode a base64 image from the image path
with open(image_path, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read())
base64_image = encoded_string.decode('utf-8')
return {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 600
}
def compose_text_payload(prompt: str) -> dict:
"""
Composes a payload dictionary with a base64 encoded image and a text prompt the standard text model.
Args:
prompt (str): The prompt text to accompany the image in the payload.
Returns:
dict: A dictionary structured as a payload for the GPT-4 Vision model, including the model name,
an array of messages each containing a role and content with text and the base64 encoded image,
and the maximum number of tokens to generate.
"""
return {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
]
}
],
"max_tokens": 600
}
The idea is to provide the possibility of asking something to OpenAI GPT-4 vision model, passing a question (i.e., the prompt) together with the image.
This was encapsulated in a new service. Therefore, on the __init__.py this new service that I called process_image:
async def async_setup(hass: HomeAssistant, config: ConfigType) -> bool:
"""Set up OpenAI Conversation."""
async def process_image(call: ServiceCall) -> ServiceResponse:
"""Process an image..."""
api_key = hass.data[DOMAIN][call.data["config_entry"]]
client = OpenAIConnector(api_key=api_key)
prompt = call.data["prompt"]
image_path = call.data["file_path"]
response = await client.simple_prompt(prompt=prompt, image_path=image_path)
return {
"response": response
}
hass.services.async_register(
DOMAIN,
SERVICE_PROCESS_IMAGE,
process_image,
schema=vol.Schema(
{
vol.Required("config_entry"): selector.ConfigEntrySelector(
{
"integration": DOMAIN,
}
),
vol.Required("prompt"): cv.string,
vol.Required("file_path"): cv.string,
}
),
supports_response=SupportsResponse.ONLY,
)
return True
...
On the services.yaml I added the description of the configuration for this new service, so that it can be used in an automation action later on.
process_image:
fields:
config_entry:
required: true
selector:
config_entry:
integration: openai_conversation_custom
prompt:
required: true
selector:
text:
multiline: true
file_path:
required: true
selector:
text:
multiline: false
I ended up having the previous functionality provided by the original OpenAI Conversation integration using its own API client together with a parallel client to support this new service. Not very clean, I know, but it works for my PoC.
Implementation
After having the custom integration installed and configured with the OpenAI API key, I created a few things in my Home Automation.
These were the main automation rules I created.
- Automation rule: take a screenshot whenever the camera detects a movement, and then analyze it using AI
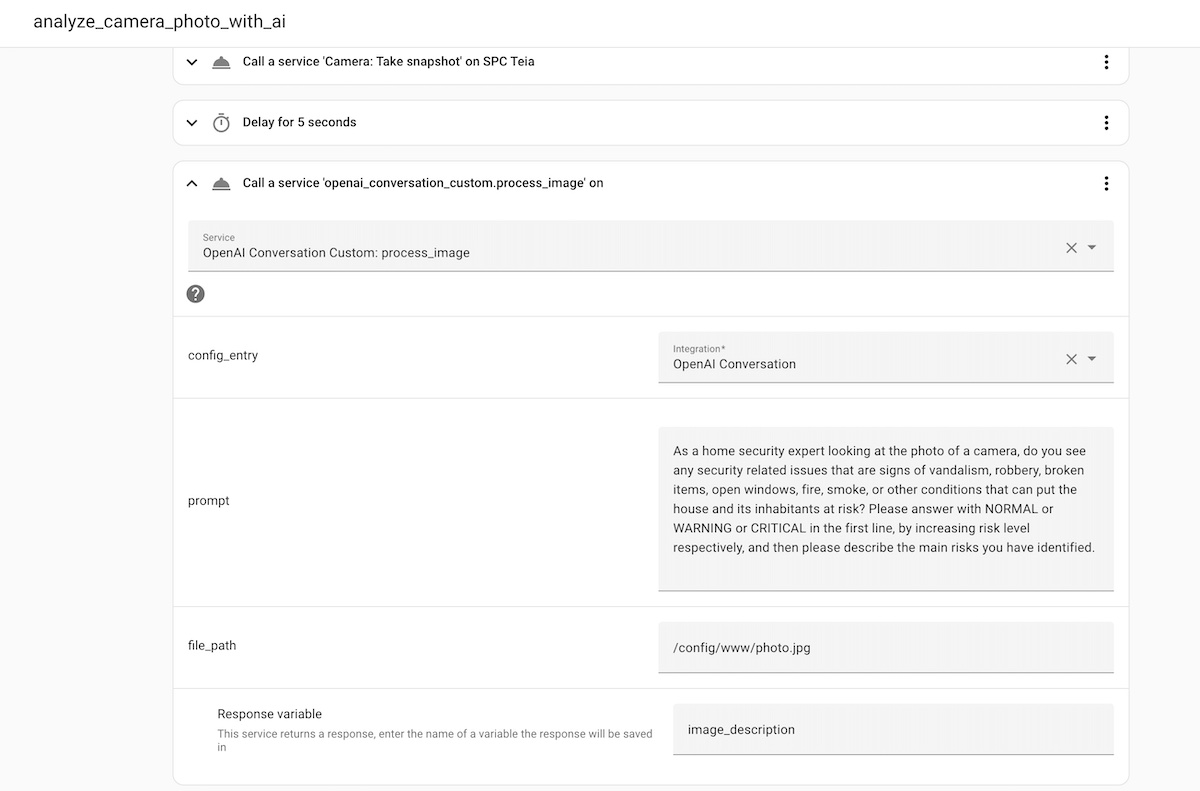
In this rule I'll use the new service that I created earlier. I have to pass a prompt. I'm using the following ones. Note that making a good prompt is essential; you can read a bit more on Prompt Engineering and some good practices.
As a home security expert looking at the photo of a camera, do you see any security related issues that are signs of vandalism, robbery, broken items, open windows, fire, smoke, or other conditions that can put the house and its inhabitants at risk? Please answer with NORMAL or WARNING or CRITICAL in the first line, by increasing risk level respectively, and then please describe the main risks you have identified.- Automation rule: notify my mobile when the image analysis changes to a certain state (e.g., "CRITICAL" or "WARNING)
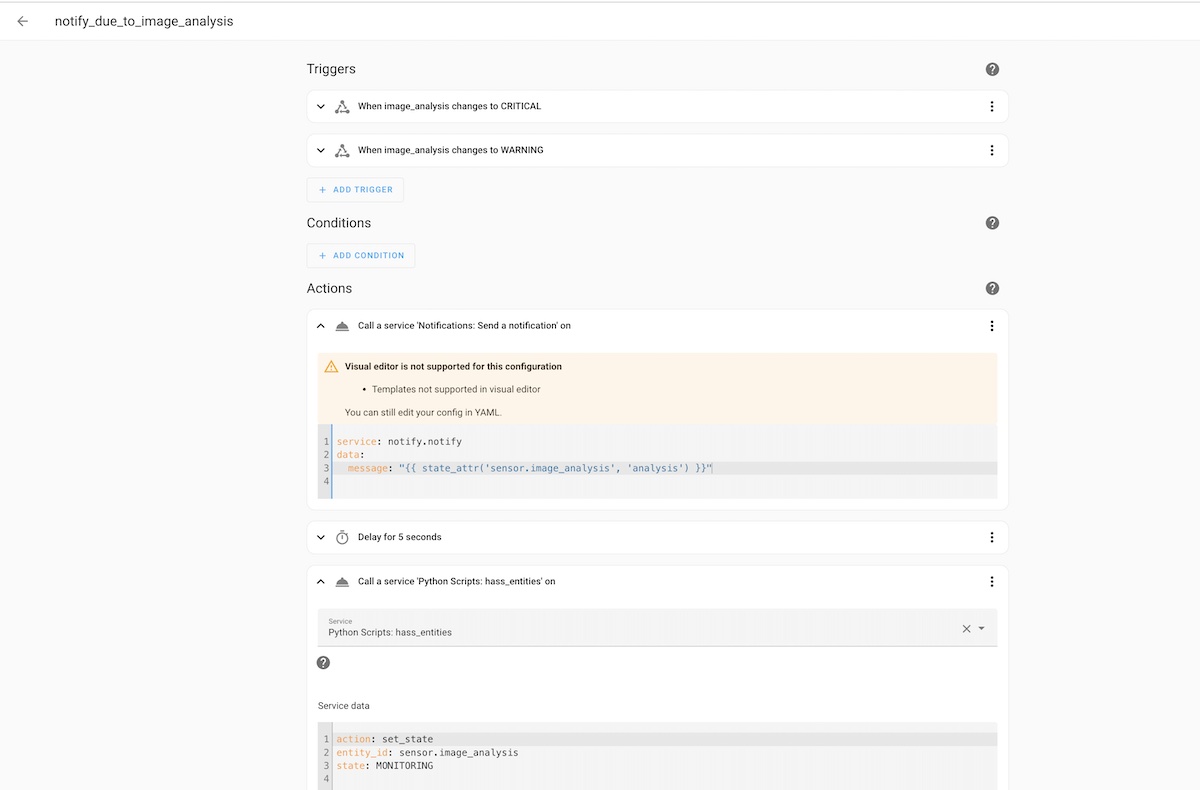
In terms of dashboard and entities, I added a few things.
To see the photo that the camera took, I used the local_file camera platform. This allowed to me overcome some issues I faced with the picture entity that wasn't able to refresh the image upon new snapshots being taken.
I also created a template based sensor entity to store the status of the image analysis. That way I can also show it on the dashboard.
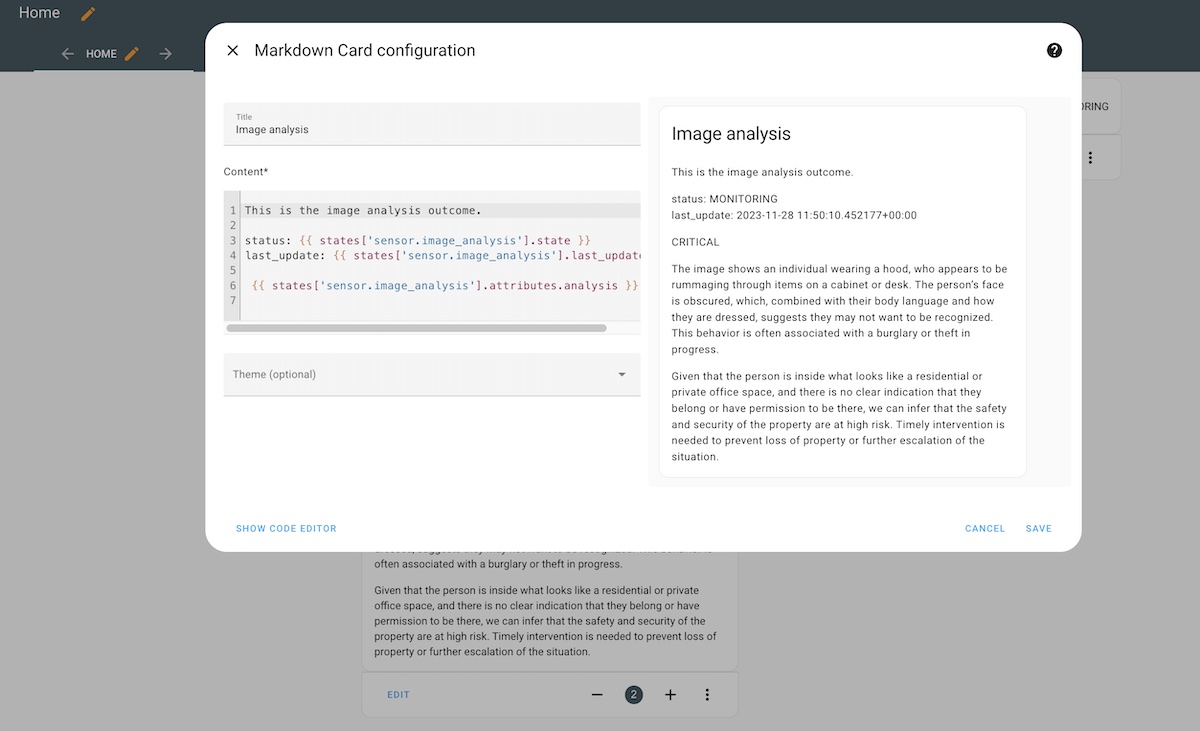
Seeing it working
After having my Home Assistant configuration worked out, I simulated someone entering the room. This was my dashboard showed.
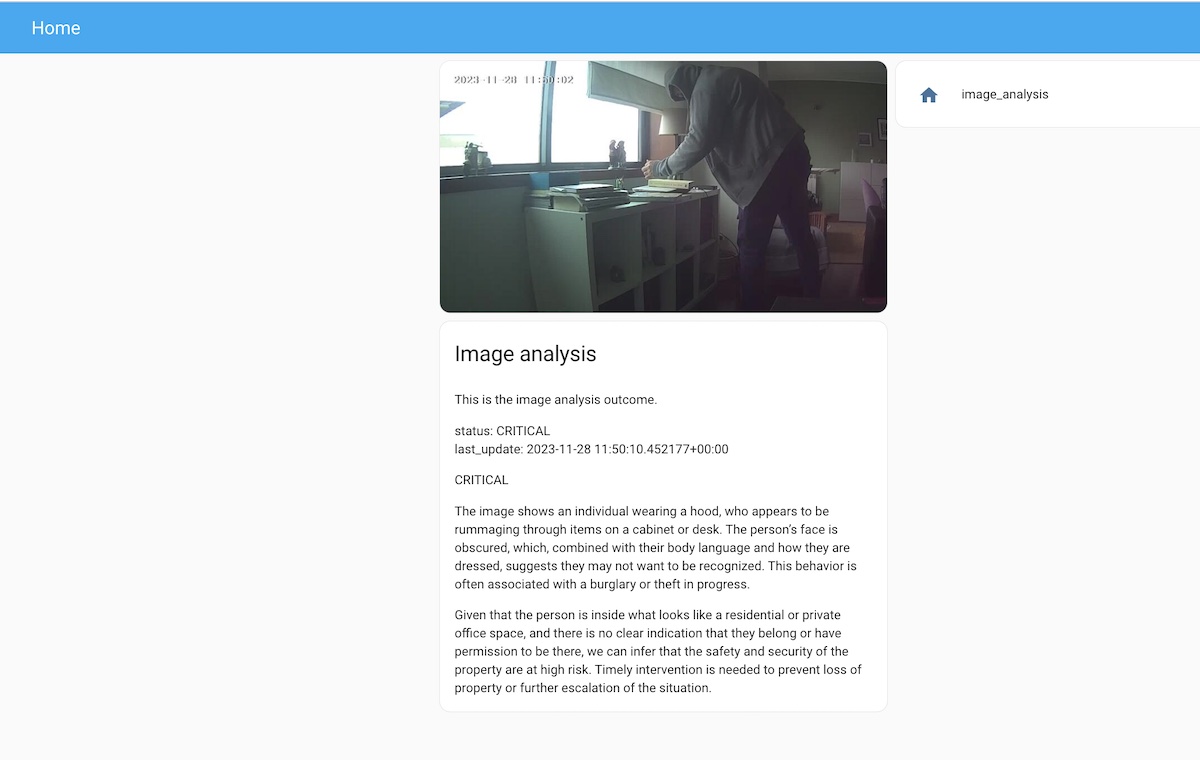
This is the mobile notification I got.
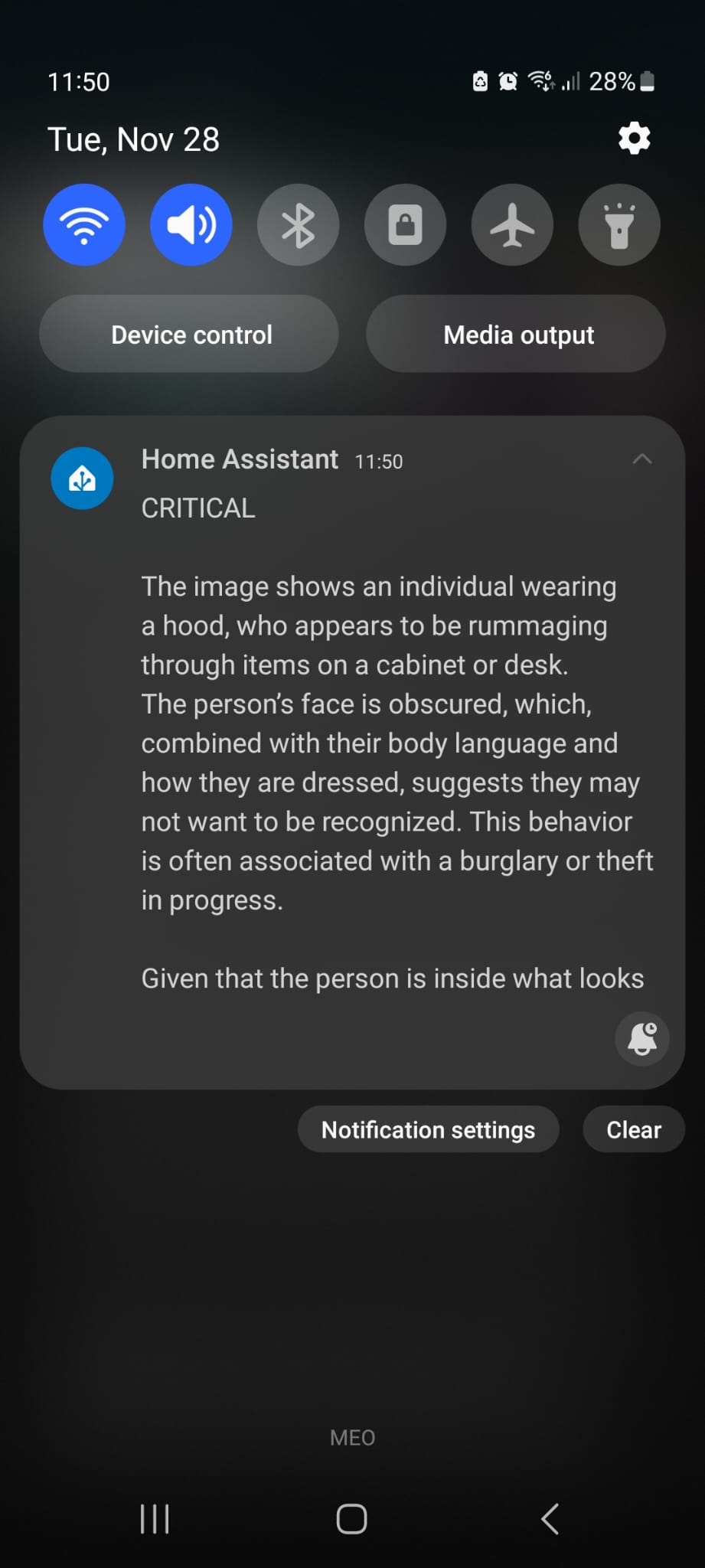
Cool, isnt' it?
Things to have in mind
There are a few things worth mentioning:
- please test the prompt you use to analyze the images; the quality of results will be highly dependent on that
- don't trust 100% on the image analysis; you can get false positives and false negatives
- test, a lot :)
- and remember, that this is just a PoC!
In sum
This small project was challenging but also fun. It shows how AI, in this case using OpenAI vision and the power of GPT-4, can be use to augment some of the the things we do, such as being used to analyze images from security cameras.
It's not a foolproof solution, but it can be used together with other data to provide some automation in your existing home automation projects! If you want to try this yourself, and since you got to this point on the tutorial, please check out the GitHub repository I put online.
Have fun!
Thanks for reading this article; as always, this represents one point in time of my evolving view :) Feedback is always welcome. Feel free to leave comments, share, retweet or contact me. If you can and wish to support this and additional contents, you may buy me a coffee ☕