Robot Framework Browser library architecture


Playwright is becoming an important browser automation library and a serious competitor or challenger to Selenium. As part of my ongoing exploration, I wanted to understand the internals of all the components and protocols involved. In this article, I'll try to deep dive the architecture, at least to a point. I won't go into an extensive explanation of the library itself, its keywords, or comparison with other libraries such as SeleniumLibrary; however, I'll touch some of those topics where it may be relevant.
Before Playwright, Selenium was the main browser automation library and SeleniumLibrary (i.e. robotframework-seleniumlibrary) was the Python package you would install for assisting on web-based testing using Robot Framework along with some specific keywords.
Meanwhile, Playwright appeared. It provides a completely different approach for automating the browser, making use of asynchronous calls and having access to and capabilities of changing some browser internals. Just as quick overview, Playwright talks to Chromium-based browsers using the Chrome DevTools Protocol (CDP), allowing you to browse and interact with web elements and also emulate devices, location, handle network events, and much more.
Architecture
In order to use the Browser Library, we need to install it as usual using "pip" and then we have to "initialize it" with "rfbrowser init". The latter command will:
- install the latest version of the playwright NPM package in our Node.js environment
- install local browsers, for chromium, webkit, and firefox browser types
Then we are ready to use Browser library in our RF tests.
The following diagram gives an overview of the underlying architecture and the flows involved when we automate our browser(s) using this library on top of Robot Framework.
This architecture may seem a bit cumbersome but there's a reason behind it. When Browser library project was started, there wasn't any Python library available for Playwright. The team decided to make a gRPC wrapper that would interact with a Node.js process where the official JavaScript "playwright" package would be running.
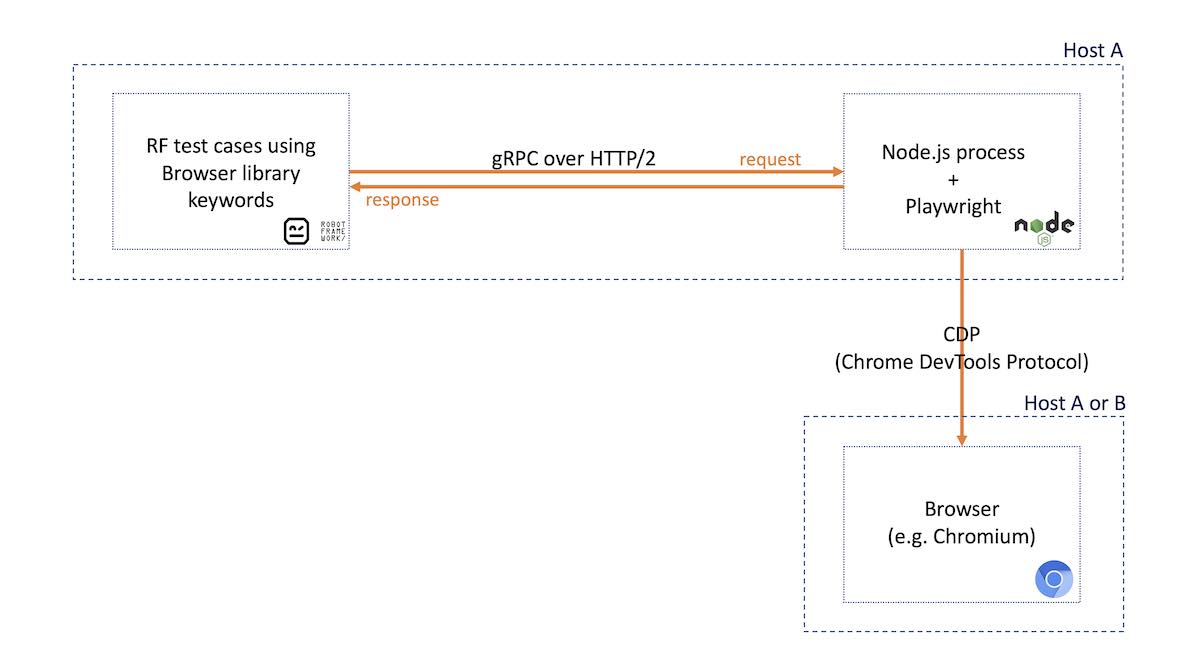
All of these components can run in the same host; eventually, the browser can be on a separate host. However, the Node.js process must run alongside with RF.
Test cases are written as usual in Robot Framework (RF) but now making use of keywords provided by the Browser library. RF usually runs in Python and Browser library can be extended using JavaScript.
Browser library, when initialized, launches a Node.js process implementing a gRPC server that will translate incoming requests to the Node.js Playwright library. Whenever using keywords of the Browser library, gRPC calls are made to the Node.js server. Messages are exchanged using Protobuf (i.e. Protocol Buffers) messages, on top of gRPC with a specific protocol/messages, which in turn works on top of HTTP/2. The Node.js gRPC server will talk directly to the browsers, using the Playwright API and specific browser protocols, such as CDP (to be discussed on an upcoming blog post).
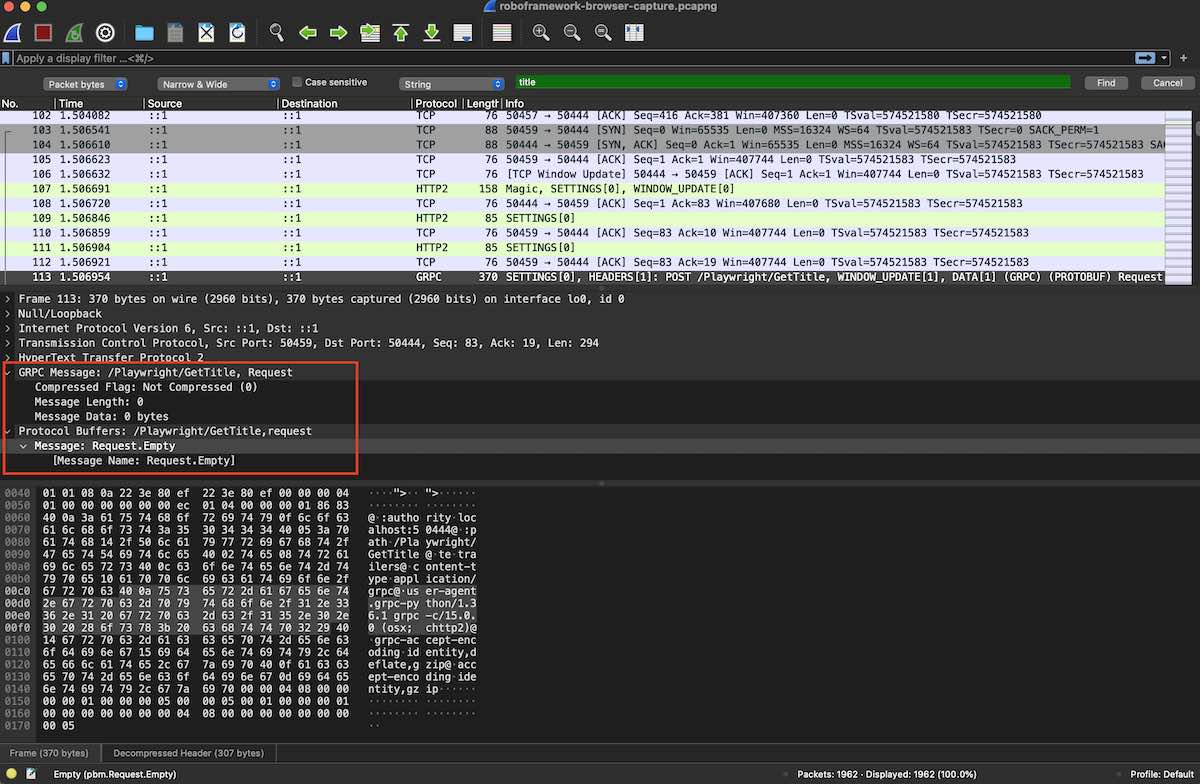
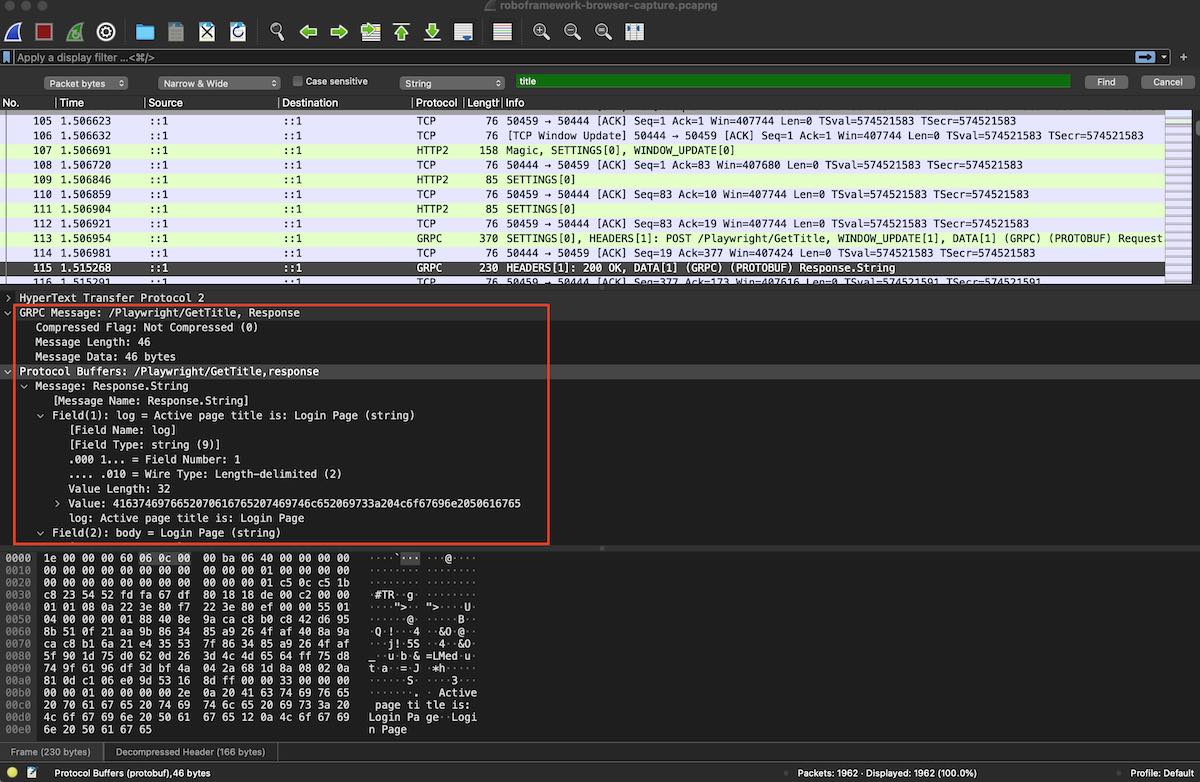
We could analyze what's going on in a simple RF test scenario that tries to obtain the page title. For that, we'll use Wireshark and install the protobuf message specification. We can see the calls between the Browser library, in our Python code, and the Node.js server that acts as a proxy to Playwright. The following screenshot shows the "Get Title" gRPC call, as a consequence of a "Get Title" keyword in RF, and the respective response.
Running tests in parallel
It's possible to use pabot to run Browser enabled tests in parallel. In this case, a browser instance will be created per each pabot process. Enhancements are being discussed to provide additional speed improvements and reuse browsers more efficiently. This may affect the previous architecture.
Comparing Selenium vs Browser libraries syntax
First, and to understand better what lies under the syntax, concepts are different, and Browser library can be said to provide finer control over the browser.
Tatu Aalto, along with Mikko Korpela, giKerkko Pelttari, René Rohner, explained this during RoboCon 2021.
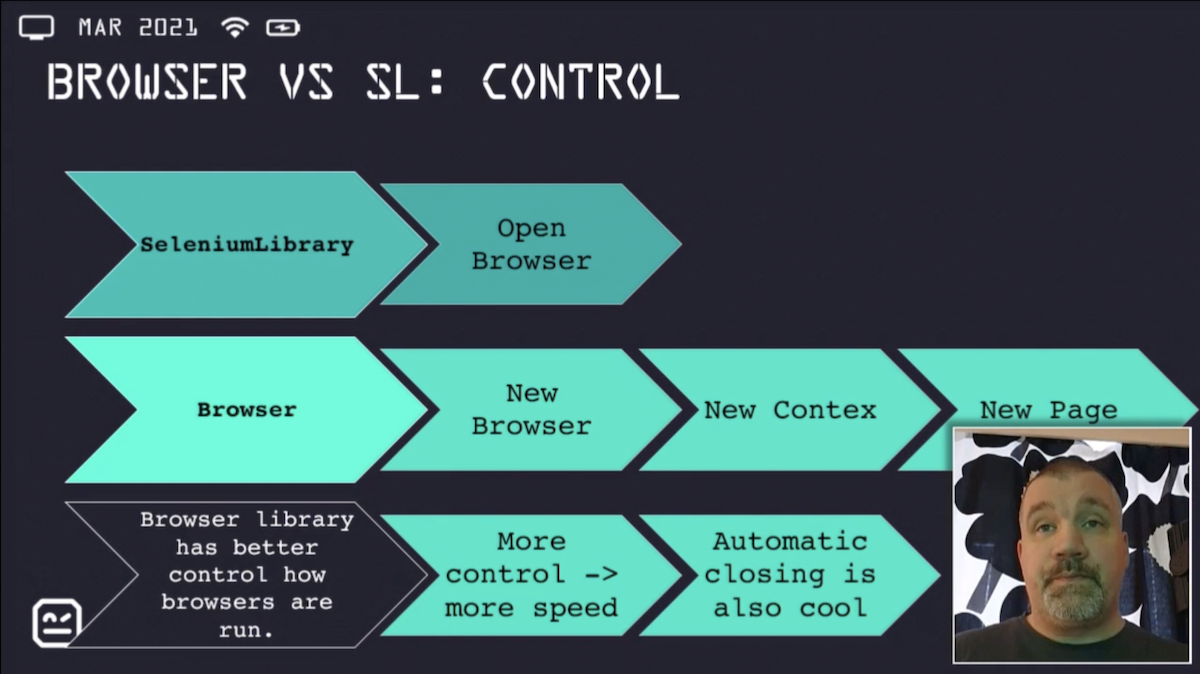
In SeleniumLibrary, all happens on top of a browser instance. We create a new browser using the "Open Browser" keyword, which in fact launches a new browser and thus takes some time and requires considerable resources. If we want to have a clean session, we close the current browser instance and have to crete a new one. On the other hand, in Browser library there are 3 layers: Browser, Context, Page.
Our browser instance is reused as much as possible, and it makes sense to create it during the init phase. Then we have "Contexts", which are configurable "incognito" like instances: they start in a clean state and are fast to create/delete. "Pages" are our typical browser tabs. If we want to have a clean session for our test, we can create a specific context for it. If we want to reuse a session between multiple tests, then we reuse the context and eventually stick its creation to the Suite Setup.
There's another interesting difference: in SeleniumLibrary we need to open and close browser and pages explicitly. Browser library handles some of this automatically: if a context or a page is created in the Test Setup/Suite Setup, then it will be automatically closed in the respective Test Teardown/Suite Teardown; the browser will be automatically closed at the end of test execution. There's a setting that allows us to finetune the behaviour of this whenever importing the library.
What concerns the syntax itself, at first sight you may not see a big difference if you have a layer of abstraction. In the following example, the .robot file with the test case is mostly the same. The only subtle change in this case is that "Close Browser" was replaced by "Close Page", even though we don't actually need to use it as mentioned earlier :)
*** Settings ***
Documentation A test suite with a single test for valid login.
...
... This test has a workflow that is created using keywords in
... the imported resource file.
Resource resource.robot
*** Test Cases ***
Valid Login
[Tags] ROB-11 UI
Open Browser To Login Page
Input Username demo
Input Password mode
Submit Credentials
Welcome Page Should Be Open
[Teardown] Close Browser
*** Settings ***
Documentation A test suite with a single test for valid login.
...
... This test has a workflow that is created using keywords in
... the imported resource file.
Resource resource.robot
*** Test Cases ***
Valid Login
[Tags] ROB-11 UI
Open Browser To Login Page
Input Username demo
Input Password mode
Submit Credentials
Welcome Page Should Be Open
# [Teardown] Close Page
The actual differences are hidden in the implementation details, in a file named "resources.robot".
Using SeleniumLibrary,
*** Keywords ***
Open Browser To Login Page
Open Browser ${LOGIN URL} ${BROWSER}
Maximize Browser Window
Set Selenium Speed ${DELAY}
Login Page Should Be Open
Login Page Should Be Open
Title Should Be Login Page
Go To Login Page
Go To ${LOGIN URL}
Login Page Should Be Open
Input Username
[Arguments] ${username}
Input Text username_field ${username}
Input Password
[Arguments] ${password}
Input Text password_field ${password}
Submit Credentials
Click Button login_button
Welcome Page Should Be Open
Location Should Be ${WELCOME URL}
Title Should Be Welcome Page
While on Browser library,
*** Keywords ***
Open Browser To Login Page
New Page ${LOGIN URL}
Login Page Should Be Open
Login Page Should Be Open
Get Title == Login Page
Go To Login Page
Go To ${LOGIN URL}
Login Page Should Be Open
Input Username
[Arguments] ${username}
Type Text id=username_field ${username}
Input Password
[Arguments] ${password}
Type Text id=password_field ${password}
Submit Credentials
Click id=login_button
Welcome Page Should Be Open
Get Url == ${WELCOME URL}
Get Title == Welcome Page
Keywords and semantics are slightly different in this case; we can say that it's easy to understand Browser library syntax and adopt it. My recommendation would be to have a look at the official documentation as it provides detailed information. Of course, Browser is different from SeleniumLibrary, and you'll find unique keywords on Browser that have no counterparts in SeleniumLibrary. One of those examples is "Promise To", one of the keywords that allows you to implement Promises (i.e. keywords that run on the background and that you can wait for them later on).
One difference that pops up, is that while SeleniumLibrary provides specific keywords for assertions (e.g. "Title Should Be"), while the Browser library approach is different: there are assertion operators (e.g. "==", "!=") that can be used for some keywords as long as they accept these as arguments (e.g. "Get Title == Welcome Page"). Meanwhile, the assertion engine has been split to a separate library: robotframework-assertion-engine.
Wrapping up
Robot Framework's Browser library is an interesting library that brings Playwright browser automation capabilities to RF users. This project uses a mix of technologies under the hood; that leads to additional requirements, including having a Node.js environment. I found out this mix interesting, as it involves different languages, frameworks, and protocols... and a workaround (using gRPC to communicate to a Node.js process) to access Playwright automation library.
The current architecture, as of v4.0.x of "robotframework-browser" package, could be eventually simplified in order to use the "playwright" Python package directly. As Kerkko Pelttari mentions, the current architecture allows to have greater control over the Playwright features available in the Browser library implementation. Depending on an upstream wrapper package for Python would add another dependency that could bring increased delays for releasing new versions; "wrapper libraries" have some lag from the main project (i.e. "playwright" NPM package in this case). Besides, changing the current architecture to use "playwright" package would also require significant refactoring. Anyway, we never know what the future brings, so it's always good to go over the release notes and the official documentation to be up to date. Playwright provides visible speed gains because it doesn't require starting new browser instances; we can simply create new contexts... and that is fast. In a simple scenario, I reduced the overall elapsed time by 50%.
If you can, I would recommend watching the Browser library talks that were part of RoboCon 2021, to learn more from the Browser library authors themselves :)
Learn more
Thanks for reading this article; as always, this represents one point in time of my evolving view :) Feedback is always welcome. Feel free to leave comments, share, retweet or contact me. If you can and wish to support this and additional contents, you may buy me a coffee ☕